SQLを書いていると、レコードの数を取得したい場面に遭遇することは多いでしょう。
レコードの数を取得するにはCOUNT関数を使います。
本記事では、実践で多用するCOUNT関数の使い方から、重複を除外した数え方やグループ化した数え方などを具体例を交えながら解説していきます。
目次
COUNT関数の使い方
COUNT関数はレコード数を取得するための文法です。検索条件に何件引っ掛かったかを数えることができます。
実践でも多用することになる関数なので使いこなせるようになると便利です。
COUNT関数の基本構文は下記です。
SELECT COUNT(*)
FROM テーブル名;SELECT文の後にCOUNT()を指定することでレコードの数を数えることができます。
*(アスタリスク)には全てという意味があるため、COUNT(*)で全てのレコードの件数を取得できます。一方で、COUNT(カラム名)とすると、カラムの値が存在するレコード数を取得できます。
この辺りの使い分けについては具体例を交えながら解説します。
サンプルデータ
下記のとおり、usersテーブルを用意します。
| id | name | address |
|---|---|---|
| 1 | 山田 | 東京都 |
| 2 | 鈴木 | 神奈川県 |
| 3 | 佐藤 | 大阪府 |
| 4 | NULL | NULL |
| 5 | 大野 | 東京都 |
| 6 | 近藤 | 大阪府 |
COUNT関数でレコード数を取得する
まずは、usersテーブルに存在するレコード数を全て取得する方法を見ていきます。
検索クエリ
usersテーブルに存在するレコード数を取得する
SELECT COUNT(*)
FROM users;先ほど解説したとおり、COUNT(*)を指定することでレコード数を全て取得できます。
実行結果
| COUNT(*) |
|---|
| 6 |
数値の6を結果として得ることができました。これは、全てのレコードの件数と一致します。
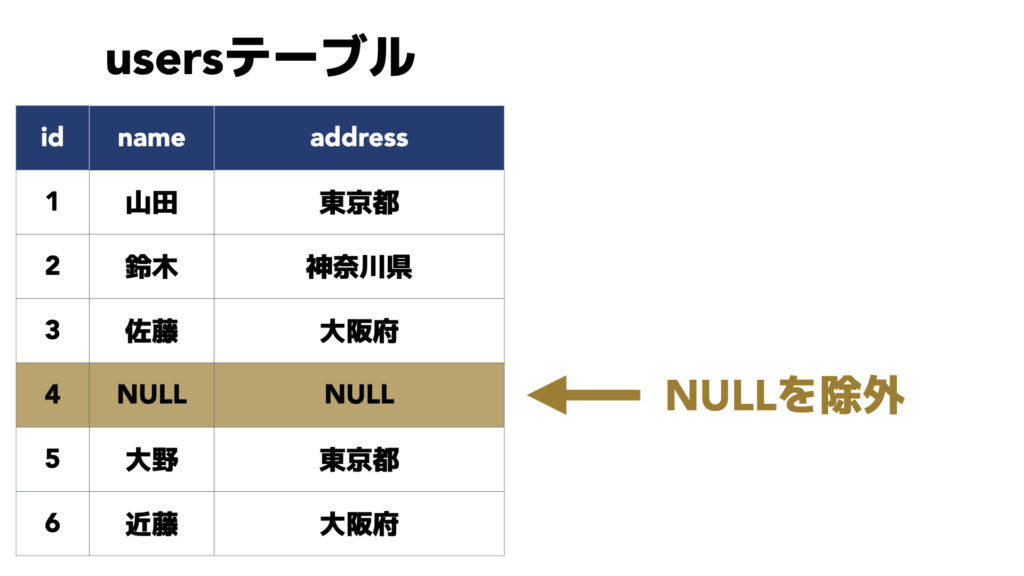
NULLを含まないレコードをカウントする方法
COUNT(*)では全てのレコードを取得しましたが、次はNULLが保存されているレコードは除外する方法を見ていきます。
結論、COUNT(*)ではなく、COUNT(カラム名)とすることでNULLを除外できます。
検索クエリ
usersテーブルから名前が存在するレコードの件数を取得する
SELECT COUNT(name)
FROM users;COUNT関数のカッコ内にnameを指定しました。すると、nameカラムの値がNULLではないレコードの件数を取得できます。
ポイントはNULLを除外したいカラムを指定することです。
実行結果
| COUNT(name) |
|---|
| 5 |
usersテーブルにはNULLが保存されているレコードが1件存在するため、その1件が除外されて数値の5を結果として得ることができました。
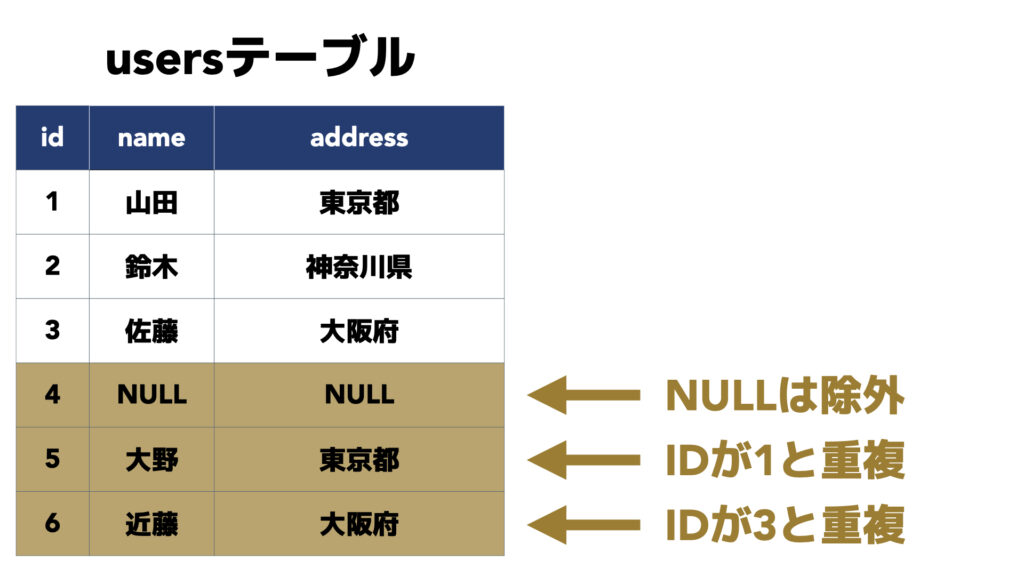
重複を除いた数をカウントする方法(DISTINCT句)
次に、値が重複するレコードは除外してカウントする方法を見ていきます。
重複の除外にはDISTINCT句を使います。
検索クエリ
住所が重複しているレコードを除外してレコードの件数を取得する
SELECT COUNT(DISTINCT address)
FROM users;COUNT関数の中でDISTINCT カラム名と指定することで、指定したカラムの値が重複するレコードを除外できます。
実行結果
| COUNT(DISTINCT address) |
|---|
| 3 |
今回の例では、IDが5と6のaddressは東京都と大阪府で、それぞれ値が重複しているので除外されました。また、NULLも除外されるため、数値の3を結果として得ることができました。
DISTINCT句については下記でまとめています。
 【SQL】DISTINCT句を使って重複を除外して検索する
【SQL】DISTINCT句を使って重複を除外して検索する
グループ化してカウントする方法(GROUP BY句)
次に、特定のカラムでグルーピングした上で、それぞれのグループに存在するレコードの数を取得する方法を見てきます。
グループ化にはGROUP BY句を使います。
検索クエリ
住所単位のレコード件数を取得する
SELECT address, COUNT(address)
FROM users
GROUP BY address;GROUP BY addressとすることで、住所ごとでグルーピングできます。また、この際NULLも一つの値としてグループ化の対象となります。
実行結果
| address | COUNT(address) |
|---|---|
| NULL | 0 |
| 大阪府 | 2 |
| 東京都 | 2 |
| 神奈川県 | 1 |
住所ごとにグループ化してそれぞれのレコード件数を取得できました。ポイントはNULLもグループ化されている点です。
NULLを除外したい場合はIS NOT NULL演算子を使って下記のようにクエリを修正します。
SELECT address, COUNT(address)
FROM users
WHERE address IS NOT NULL
GROUP BY address;IS NOT NULL演算子を使うことでNULLの値が保存されているレコードを除外できます。
GROUP BY句については下記でまとめています。
 GROUP BY句を使って集計!COUNTやHAVINGとの合わせ技も解説【SQL】
GROUP BY句を使って集計!COUNTやHAVINGとの合わせ技も解説【SQL】
IS NOT NULL句も下記でまとめています。
 【SQL】IS NULL演算子の使い方を解説!ややこしいNULLの概念を理解しよう
【SQL】IS NULL演算子の使い方を解説!ややこしいNULLの概念を理解しよう
WHERE句の中で数を数える方法【COUNT関数は使えない】
SQLの検索条件の中にレコードの件数を含めたい場合があります。
例えば、先ほど住所でグループ化を行いましたが、グループに2件以上のレコードが存在するデータだけ取得したいといったケースが考えられます。
一番最初に思いつくのはWHERE句を使って下記のように書くやり方です。
SELECT address, COUNT(address)
FROM users
WHERE COUNT(address) > 1
GROUP BY address;しかし、これでは文法エラーが出てしまいます。
WHERE句の中でCOUNT関数を使うことができないのです。
よって、COUNT関数を使って検索条件をしたい場合はWHERE句ではなく、HAVING句を使います。HAVING句もWHERE句と同じく検索条件を指定する文法です。
WHERE句がGROUP BY句の前に書く必要があるのに対して、HAVING句はGROUP BY句よりも後に記載する必要があります。
SELECT address, COUNT(address)
FROM users
GROUP BY address
HAVING COUNT(address) > 1;これは、COUNT関数を使った集計処理がグループ化等の処理の後に行われる必要があるためです。COUNT関数だけでなくその他の集約関数と呼ばれるSUM関数、MAX関数、AVG関数などもWHERE句の中で使用することはできません。
内容のまとめ
- COUNT関数を使うことでレコードの件数を取得できる
COUNT(*)で全てのレコードの件数を取得できるCOUNT(カラム名)でNULLの値が存在するレコードを除外した件数を取得できる- 重複を除いたレコード件数を取得したい場合は、
COUNT(DISTINCT カラム名)とDISTINCT句を使う - グループ化してレコード件数を取得したい場合は、GROUP BY句を使う
- WHERE句の中でCOUNT関数を使うことはできないため、代わりにHAVING句を使う

